Archive for the 'XSLT' Category
Adobe AIR and XSLT… Again 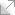
August 12th, 2007
I just thought that I should voice my disappointment once more regarding the fact that Adobe as yet has not confirmed that XSLT is going to be included in the final release of AIR. This is particularly strange given that it is included in the version of WebKit that is being used by AIR.
As usual I have been thinking of a cool application that would be well suited to a simple cross platform desktop widget, only problem being that it requires XSLT for high speed grouping and filtering of data. Normally, data for an AIR application might be accessed through some “web service” but in this case it is accessed natively as XML from the file system. If AIR does not have XSLT support it makes it much more difficult to make compelling and richly interactive applications for the desktop.
Posted in Uncategorized, XSLT, air | 2 Comments »
Declarative Ajax and Flex Interop
July 3rd, 2007
This is some code that I wrote about a year ago at the Flex Component Developers Summit (and more recently presented at XTech) to show how declarative Ajax and Flex can work together to create dynamic, rich and compelling Internet applications.
The idea is simple. Take a single declaration - in this case XHTML - of some user-interface component and then use it to build a UI using either Ajax or Flex. All this from just one declaration.
What happens is that we take a single declarative data grid and converts it using XSLT on the client (so it only works Firefox, IE and soon Safari) into a declarative Nitobi Ajax Grid and to a Flex declarative MXML DataGrid. I use the FABridge to get the string of MXML generated from the XSL transformation into a stub Flex application where a Flex DataGrid is instantiated (deserialized) from the MXML declaration. It can an be seen live here (note: create the Flex grid first then the Ajax one - something funny that I can’t be bothered to fix  ) and the code can be downloaded from here.
) and the code can be downloaded from here.
So by using a declarative approach and a little XSLT on the client we were able to quickly choose between using a Flex DataGrid or a Nitobi Ajax Grid to display our tabular data in!
Really the most interesting part is the MXML deserialization stuff. The only contents of the Flex application are two functions for performing the deserialization. I have listed the main part of the code that takes an XML document of an MXML DataGrid declaration and actually instantiates a DataGrid according to that declaration. It’s pretty quick and dirty but at least gets the right thing out! Essentially it just looks at each XML element and creates an Object out of it and sets all the properties on it from the XML element attributes and then recurses through the child elements doing the same. There are some special attributes though like datasources that need a little more care.
public function initGrid(html) {
// setup a tagname to datatype hash - maybe this already exists somewhere
controls['DataGrid'] = 'mx.controls.DataGrid';
controls['ArrayCollection'] = 'mx.collections.ArrayCollection';
controls['Object'] = 'Object';
controls['columns'] = 'Array';
controls['DataGridColumn'] = 'mx.controls.dataGridClasses.DataGridColumn';
// load the HTML into XML DOM
var mxml:XML = new XML('<root>'+html+'</root>');
parseXml(AjaxBox, mxml);
}
public function parseXml(parent, mxml) {
var item:String;
// get all the elements in our XML doc - this should of course walk the xml tree recursively
var itemList:XMLList = mxml.elements('*');
for (item in itemList) {
// get the tag name of the XML node
var tagName:String = itemList[item].localName();
// get the class by using getDefinitionByName() method
var ClassReference:Class = Class(getDefinitionByName(controls[tagName]));
// create an instance of the class
var myObject:Object = new ClassReference();
// get all the attributes and set the properties
var attrList:XMLList = XML(itemList[item]).attributes();
for (var attr:String in attrList) {
myObject[attrList[attr].localName()] = attrList[attr].toString();
}
// now parse the children of this node
parseXml(myObject, itemList[item]);
if (parent.hasOwnProperty(tagName)) {
parent[tagName] = myObject;
} else if (parent.hasOwnProperty("length")) {
if (parent.hasOwnProperty("source")) {
parent.source.push(myObject);
} else {
parent.push(myObject);
}
} else if (parent.hasOwnProperty("dataProvider") && tagName == "ArrayCollection") {
// This means we need to create a datasource for the Grid
parent.dataProvider = myObject;
} else {
parent.addChild(DisplayObject(myObject));
}
}
}
Posted in Web2.0, AJAX, XSLT, Flash, Flex, Declarative Programming, Components, Grid, RIA, FABridge | 1 Comment »
Grid With AIR and Safari 3
June 14th, 2007
With the release of Safari 3 Beta and the recent renaming and Beta release of AIR (formerly Apollo) from Adobe, we have started to work on getting our components running in both of them.
We have run across a few problems - the biggest of which is the lack of any decent debugging tools for either one. I am sure that this will soon change. Currently the best thing around for debugging is Scout.
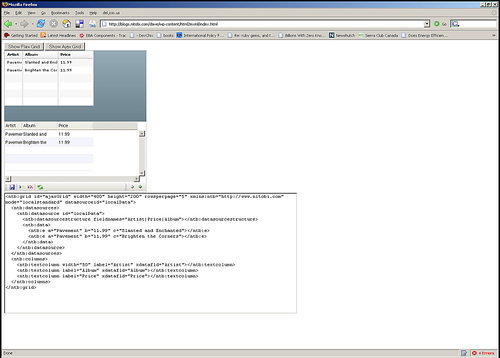
Grid is being a bit of a challenge given that there is no XSLT support in AIR - though there is in Safari 3. Jake and I got it almost working with a day or so of work / screaming at our computers. Here is a screenshot of what we got so far:
We are pretty happy with the progress and the fact that no one has been hurt - yet
There a few known problems in AIR currently such as CSS opacity not working, table width=0px with colgroups does not work and a few other small things like that. We are certainly happy that Safari 3 and AIR both support addRule and insertRule for working with CSS while a little disappointed in no XSLT support in AIR yet good support in Safari 3.
Posted in Web, AJAX, XSLT, Components, Nitobi, apollo, completeui, air, safari | No Comments »
XML vs JSON: A Second Sober Look
January 8th, 2007
There has been a recent fleury of discussion about XML vs JSON. What a great topic for the holidays.
Although I have been talking about this topic for some time, some XML bloggers have recently started to discuss the topic (Tim Bray, Don Box, David Megginson, Dare Obsanjo and all the comments). For the most part the discussion is pretty tame and nothing really new.
Tim brings up the good points about extensibility and encoding. He also importantly acknowledges the fact that JSON is applicable in certain cases. To his points I would add the fact that one is able to use XPath with XML making it very powerful for quickly finding data. XPath is one XML technology that many ignore, particularly in the JavaScript sandbox.
The other important points are really in direct response to Dare Obsanjo’s posts from last week: Browser Security Model and Browser Programming Model. First of all, Dare suggests that one reason for JSON being so popular is due to cross-domain JSON (also called JSONP or JSON with Padding). Ignoring the data format, this pattern is applicable to any kind of data, including XML (XML with Padding is equally valid). There is no reason that Yahoo! could not provide a cross-domain XML API along side a cross-domain JSON API. In fact, I urge people to email everyone they know over at Yahoo! to do so for all their properties such as del.icio.us.
There are also a few points I have in response to the second post about the difference between the programming models of JSON and XML. The main thing that I noticed is that the example presents is not a realistic use case. What is most commonly done with data in an Ajax application is that the data is rendered to HTML. The fastest way to render data to HTML is using XML and XSLT. The other thing that he does not look at is cases where the data needs to be sorted or filtered, in which case XML and either XSLT or XPath provide a very nice solution. Of less importance, Dare also states that one should use a JSON parser in case of security concerns, however, the JavaScript based JSON parsers that I have used have had very extremely poor performance - even worse than plain eval().
The other interesting thing was a comment made by Kevin Hackman from TIBCO in the Ajaxian post. Kevin mentioned the fact that TIBCO uses XML to maintain the JavaScript state - i.e. each JavaScript object has a related XML document where the the object properties are stored and accessed using standard JavaScript accessor methods - which helps in terms of application memory usage. This is something that the soon to be released Nitobi Complete UI Framework also does, although for slightly different reasons like the fact that objects can then be easily serialized for use with server frameworks like JSF or ASP.NET.
At any rate, I am happy to see that some others are joining in on the discussion and if nothing else I hope that people start to talk more about using XSLT and XPath in the browser.
Posted in AJAX, XML, XSLT, Declarative Programming, Performance, markup | 7 Comments »
Help Wanted!
February 22nd, 2006
Once again, we are hiring some more AJAX developers. Anyone out there with mad AJAX skills or the work ethic to rapidly get up to speed on some exciting AJAX product development?
If so please email us!
Here is the full job description.
With that corporate malarky out of the way I just want to mention something about who we _really_ are.
We are dedicated ajax developers who take pride in high performance and user centric products. If you want to be challenged in a startup like environment with lots of responsibility (and reward) then this is the place to be. Although we work hard, as the saying goes, we also play hard. If we are not pushing the limits of JavaScript and XSLT then we are taking in everything that Vancouver has to offer like the mountains right in our backyard, the ocean at our feet and a beer in our hands. We are trying to build a place where people can grow not only as individuals but as part of a larger team in the business and as members of the Vancouver tech, web and social communities. We operate with our core values laid plain for everyone to see and expect the same openess and honesty from every one of our team members.
If you have what it takes then really please do email us!
Posted in Web2.0, AJAX, JavaScript, XML, XSLT, Business | No Comments »
XML with Padding
January 27th, 2006
So Yahoo! supports the very nice JSONP data formatting for returning JSON (with a callback) to the browser - this of course enables cross domain browser mash-ups with no server proxy.
My question to Yahoo! is then why not support XMLP? I want to be able to get my search results in XML so that I can apply some XSLT and insert the resulting XHTML into my AJAX application. I am hoping that the “callback” parameter on their REST interface will soon be available for XML. It would be essentially the exact same as that for JSON and would call the callback after the XML data is loaded into an XML document in a cross-browser fashion. While that last point would be the most sticky it is, as everyone knows, dead simple to make cross browser XML documents 
Please Yahoo! give me my mash-up’able XML!
If you want to make it really good then feel free to either return terse element names (like “e” rather than “searchResult” or something like that) or add some meta-data to describe the XML (some call it a schema but I am not sure JSON people will be familiar with it  ) so that people will not complain about how “bloated” the XML is. For example:
) so that people will not complain about how “bloated” the XML is. For example:
<metadata>
<searchResult encoding=”e” />
</metadata>
<data>
<e>Search result 1</e>
<e>Search result 2</e>
<e>Search result 3</e>
<e>Search result 4</e>
<e>Search result 5</e>
<e>Search result 6</e>
</data>
Come on Yahoo! help me help you!
Posted in Web2.0, AJAX, JavaScript, XML, XSLT | 2 Comments »
XML/XSLT in Mozilla
January 17th, 2006
I had just clicked the “save and preview” button and lost my entire post … anyhow I will give it another shot but it will surely not be anywhere as lucid given my rising urge to kill
Given that we have been developing AJaX solutions for some time now based on Internet Explorer it is becoming a wee bit annoying that we have to cater so much to the Firefox/Mozilla using crowd simply because they are the most vocal and influential! Luckily most of our customers still use Internet Explorer. Nonetheless we are doing our best and hope to have a cross browser architecture for our AJaX components very soon. In so doing, I have been having a fun time figuring our XPath and XSLT in Mozilla so that it emulates Internet Explorer (I will likely just end up using sarissa in the end though). Having gone through most of this process, I finally understand why the majority of Mozilla developers hate XML/XSLT and love JSON! It also helps that MSDN has such great documentation I guess as well :S
Most of this work has been in an effort to create a small library that I call J4X - JSON for XML - which essentially dynamically creates a JavaScript object representing the XML behind it. This liberates developers from having to use XML interfaces to access their objects and insteads makes it just like JSON. So you get the best of both worlds - easy programatic access and XML based message formatting! In that respect it is more or less a stop-gap technology until E4X becomes more widely supported.
Posted in AJAX, XML, XSLT | 2 Comments »
JSON Benchmarking: Beating a Dead Horse
December 21st, 2005
There has been a great discusson over at Quirksmode [1] about the best response format for your data and how to get it into your web application / page. I wish that I had the time to respond to each of the comments individually! It seems that PPK missed out on the option of using XSLT to transform your XML data to an HTML snippit. In the ensuing discussion there were only a few people mentioning XSLT and many of them just to say that it is moot! I have gone over the benefits of XSLT before but I don’t mind going through it once more Just so everyone knows, I am looking at the problem _primarily_ from the large client side dataset perspective but will highlight areas where JSON or HTML snippits are also useful. Furthermore, I will show recent results from JSON vs XSLT vs XML DOM in Firefox 1.5 on Windows 2000 and provide the benchmarking code so that everyone can try it themselves (this should be up shortly - just trying to make it readable).
As usual we need to take the “choose the right tool for the job” stance and try to be objective. There are many dimensions that tools may be evaluated on. To determine these dimensions let’s try and think about what our goals are. At the end of the day I want to see scaleable, useable, re-useable and high performance applications developed in as little time and for as little money as possible.
End-User Application Performance
In creating useable and high performance web applications (using AJAX of course) end-users will need to download a little bit of data up front to get the process going (and they will generally have to live with that) before using the application. While using the application there should be as little latency as possible when they edit or create data or interact with the page. To that end, users will likely need to be able to sort or filter large amounts of data in table and tree formats, they will need to be able to create, update and delete data that gets saved to the server and all this has to happen seemlessly. This, particularly the client side sorting and filtering of data, necessitates fast data manipulation on the client. So the first question is then what data format provides the best client side performance for the end-user.
HTML snippits are nice since they can be retieved from the server and inserted into your application instantly - very fast. But you have to ask if this achieves the performance results when you want to sort or filter that same data. You would either have to crawl through the HTML snippit and build some data structure or re-request the data from the server - if you have understanding users who don’t mind the wait or have the server resources and bandwidth of Google then maybe it will work for you. Furthermore, if you need fine grained access to various parts of the application based on the data then HTML snippits are not so great.
JSON can also be good. But as I will show shortly, and have before, it can be slow since the eval() function is slow and looping through your data creating bits of HTML for output is also slow. Sorting and filtering arrays of data in JavaScript can be done fairly easily and quickly (though you still have to loop through your data to create your output HTML) and I will show some benchmarks for this later too.
XML DOM is not great. You almost might as well be using JSON if you ask me. But it can have it’s place which will come up later.
XML + XSLT (XAXT) on the other hand is really quite fast in modern browsers and is a great choice for dealing with loads of data when you need things like conditional formatting and sorting abilities right on the client whithout any additional calls to the server.
System Complexity and Developement
On the other hand, we also have to consider how much more difficult it is to create an application that uses the various data formats as well as how extensible the system is for future development.
HTML snippits don’t really help anyone. They cannot really be used outside of the specific application that they are made for but when coupled with XSLT on the server can be useful.
JSON can be used between many different programming languages (not necessarily natively) and there are plenty of serializers available. Developers can work with JSON fairly easily in this way but it cannot be used with Web Services or SOA.
XML is the preferred data format for Web Services, many programming languages, and many developers. Java and C# have native support to serialize and de-serialize from XML. Importantly on the server, XML data can be typed, which is necessary for languages like Java and C#. Inside the enterprise, XML is the lingua franca and so interoperability and data re-use is maximized, particularly as Service Oriented Architecture begins to get more uptake. XSLT on the server is very fast and has the advantage that it can be used, like XML, in almost any porgamming language including JavaScript. Using XSLT with XML can have problems in some browsers but moving the transformations to ther server is one option, however, this entails more work for the developer.
Other factors
- The data format should also be considered due to bandwidth concerns that affects user-interface latency. Although many people say that XML is too bloated it can easily be encoded in many cases and becomes far more compact than JSON or HTML snippits.
- As I mentioned XML can be typed using Schemas, which can come in handy.
- Human readability of XML also has some advantages.
- JSON can be accessed across domains by dynamically creating script tags - this is handy for mash-ups.
- Standards - XML.
- Since XML is more widely used it is easier to find developers that know it in case you have some staff turnover.
- Finally, ECMAScript for XML (E4X) is a _very_ good reason to use XML [2]!
Business Cases
There are various business cases for AJAX and I see three areas that differentiate where one data format should be chosen over the other and these are: mash-ups or the public web (JSON can be good), B2B (XML), and internal corporate (XML or JSON). Let’s look at some of the particular cases:
- if you are building a service only to be consumed by your application in one instance then go ahead and use JSON or HTML (public web)
- if you need to update various different parts of an application / page based on the data then JSON is good or use XML DOM
- if you are building a service only to be consumed by JavaScript / AJAX applications then go ahead and use JSON or a server-side XML proxy (mash-up)
- if you are building a service to be consumed by various clients then you might want to use something that is standard like XML
- if you are building high performance AJAX applications then use XML and XSLT on the client to reduce server load and latency
- if your servers can handle it and you don’t need interaction with the data on the client (like sorting, filtering etc) then use the XSLT on the server and send HTML snippits to the browser
- if you are re-purposing your corporate data to be used in a highly interactive and low latency web based application then you had better use XML as your data message format and XSLT to process the data on the client without having to make calls back to the server - this way if the client does not support XSLT (and you don’t want to use the _very slow_ [3] Google XSLT engine) then you can always make requests back to the server to transform your data.
- if you want to have an easy time finding developers for your team then use XML
- if you want to be able to easily serialize and deserialize typed data on the server then use XML
- if you are developing a product to be used by “regular joe” type developers then XML can even be a stretch
I could go on and on …
Performance Benchmarks
For me, client side performance is one of the biggest reasons that one should stick with XML + XSLT (XAXT) rather than use JSON. I have done some more benchmarking on the recent release of Firefox 1.5 and it looks like the XSLT engine in FF has improved a bit (or JavaScript became worse).
The tests assume that I am retrieving some data from the server which is returned either as JSON or XML. In XML I can use the responseXML property of the XMLHTTPRequest object to get an XML object which can subsequently be transformed using a cached stylesheet to generate some HTML - I only time the actual transformation since the XSLT object is a singleton (ie loaded once globally at application start) and the responseXML property should have little effect different from the responseText property. Alternatively the JSON string can be accessed using the responseText property of the XMLHTTPRequest object. For JSON I measure the amount of time it takes to call the eval() function on the JSON string as well as the time it takes to build the output HTML snippit. So in both cases we start with the raw output (in either text or XML DOM) from the XMLHTTP and I measure the parts needed to get from there to a formatted HTML snippit.
Here is the code for the testJson function:
function testJson(records)
{
//build a test string of JSON text with given number of records
var json = buildJson(records);
var t = [];
for (var i=0; i<tests ; i++)
{
var startTime = new Date().getTime();
//eval the JSON string to instantiate it
var obj = eval(json);
//build the output HTML based on the JSON object
buildJsonHtml(obj);
t.push(new Date().getTime() - startTime);
}
done(’JSON EVAL’,records,t);
}
As for the XSLT test here it is below:
function testXml(records)
{
//build a test string of xml with given number of records
var sxml = buildXml(records);
//load the xml into an XML DOM object as we would get from XMLHTTPObj.responseXML
var xdoc = loadLocalXml(sxml, “4.0″);
//load the global XSLT
var xslt = loadXsl(sxsl, “4.0″, 0);
var t = [];
for (var i=0; i<tests ; i++)
{
var startTime = new Date().getTime();
//browser independent transformXml function
transformXml(xdoc, xslt, 0);
t.push(new Date().getTime() - startTime);
}
done(’XSLT’,records,t);
}
Now on to the results … the one difference from my previous tests is that I have also tried the XML DOM method as PPK suggested - the results were not that great.
For IE 6 nothing has changed of course, except that we can see using XML DOM is not that quick, however, I have not tried to optimise this code yet.
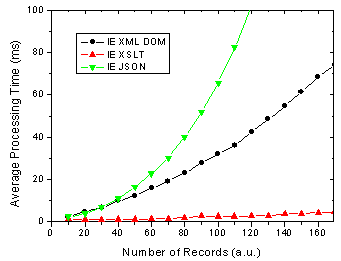
Figure 1. IE 6 results for JSON, XML DOM and XML + XSLT.
On the other hand, There are some changes for FF 1.5 in that the XSLT method is almost as fast as the JSON method. In previous versions of FF XSLT was considerably faster [4].
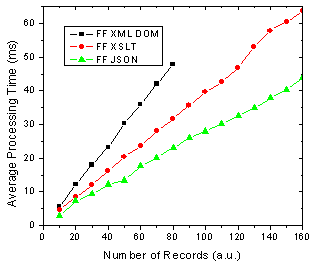
Figure 2. FF 1.5 results for JSON, XML DOM and XML + XSLT.
What does all this mean you ask? Well as before I am assuming that the end-users of my application are going to use FF 1.5 and IE 6 in aboutl equal numbers, 50-50. So this might be a public AJAX application on the web say whereas the division could be very different in a corporate setting. Below shows the results of this assumption and it shows that almost no matter how many data records you are rendering, XSLT is going to be faster given 50-50 usage of each browser.
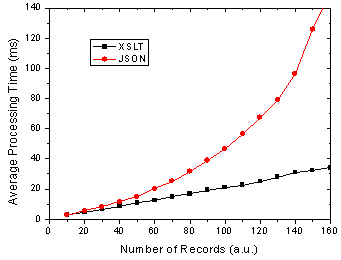
Figure 3. Total processing time in FF and IE given 50-50 usage split.
I will have the page up tomorrow I hope so that everyone can try it themselves - just need to get it all prettied up a bit so that it is understandable
References
[1] The AJAX Response: XML, HTML or JSON - Peter-Paul Koch, Dec 17, 2005
[2] Objectifying XML - E4X for Mozilla 1.1 - Kurt Cagle, June 13, 2005
[3] JavaScript Benchmarking - Part 3.1 - Dave Johnson, Sept 15, 2005
[4] JavaScript Benchmarking IV: JSON Revisited - Dave Johnson, Sept 29, 2005
Posted in Web2.0, AJAX, JavaScript, XML, XSLT, JSON | 21 Comments »
JavaScript Benchmarking IV: JSON Revisited
September 29th, 2005
My last post [1] about JSON had a helpful comment from Michael Mahemoff, the driving force behind the great AJaX Patterns site (I recommend taking a quick gander at the comments/responses from/to Michael and Dean who are both very knowledgeable in the AJaX realm).
Experimental: Comparing Processing Time of JSON and XML
Michael had commented that there was a JavaScript based JSON parser that is an alternative to using the native JavaScript
eval()
function which provides a more secure deserialization method. So I put the JSON parser to the test in both IE 6 and Firefox and compared it to using
eval()
as well as using XML. The results are shown below:
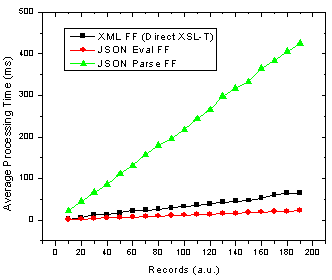
Figure 1. JSON parse and eval() as well as XML transformation processing time with number of records in Firefox.
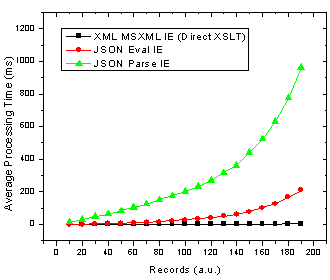
Figure 2. JSON parse and eval() as well as XML transformation processing time with number of records in Internet Explorer.
Ok so it’s pretty clear that the JSON parser is by far the slowest option in both browsers! The result that muddies the water is that in Firefox using JSON with the
eval()
function is actually the fastest method. These results also re-inforce those I found in an earlier JavaScript benchmarking post [2] which revealed that JavaScript was faster than XSL-T for building an HTML table in Firefox but not in IE 6.
Analysis: Implications of Varying DataSet Size
Now, to make it crystal clear that I am not simply saying that one method is better than another I will look at what this means for choosing the proper technology. If you look at browser usage stats from say W3Schools, then we can determine the best solution depending on the expected number of records you are going to be sending to the browser and inserting into HTML. To do this I divide each set of data by the browser usage share and then add the JSON Firefox + JSON Internet Explorer processing times and do the same for the XML data. This then gives the expected average processing time given the expected number of people using each browser. The results are below.
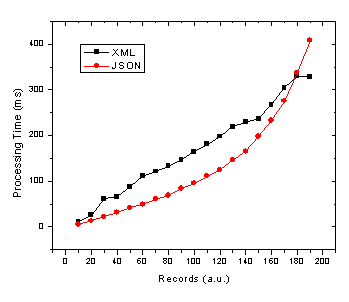
Figure 3. JSON and XML average processing time against record number given 72% and 20% market share of Internet Explorer and Firefox/Mozilla respectively.
Due to the apparent x^2 / exponential dependence of JavaScript / JSON processing time on the number of records in IE (see Fig. 2) it is no wonder that as we move to more records the JSON total average processing time increases in the same manner. Therefore, the JSON processing time crosses the more linear processing time for XML at somewhere in the neighbourhood of 180 records. Of course this exact cross-over point will change depending on several factors such as:
- end user browser usage for your application
- end user browser intensity (maybe either IE or FF users will actually use the application more often due to different roles etc)
- end user computer performance
- object/data complexity (nested objects)
- object/data operations (sorting, merging, selecting etc)
- output HTML complexity
Keep in mind that this will all could all change with the upcoming versions of Internet Explorer and Firefox in terms of the speed of their respective JavaScript and XSL-T processors. Still there are also other slightly less quantitative reasons for using XML [1,3] or JSON.
References
[1] JSON and the Golden Fleece - Dave Johnson, Sept 22, 2005
[2] JavaScript Benchmarking - Part I - Dave Johnson, July 10, 2005
[3] JSON vs XML - Jep Castelein, Sept 22 2005
Posted in Web2.0, AJAX, JavaScript, XML, XSLT | 12 Comments »
JSON and the Golden Fleece
September 22nd, 2005
JavaScript Object Notation (JSON) is a clever, AJaXian way of representing data for use in a web browser that supports the JavaScript programming language. However, like the golden fleece (and the fair Medea) retrieved by Jason in Greek mythology, I believe that in time it will be forgotten. Gotta love all the AJaX Greek cliches!
People have before argued that JSON is a good alternative to XML for many reasons. Here are my reasons for why I prefer XML.
Processing
First and foremost, something really irks me about using
eval()
in JavaScript to create objects. This can be a both a security problem and, despite what many people seem to think (I am not sure who started it), it is relatively slow, particularly as you start having nested objects. Meanwhile XML can be deserialized into objects in most OO languages and / or formatted using XSL-T (using JavaScript for example) to create any XML dialect one wishes (such as XHTML for AJaX purposes). Furthermore, in the realm of AJaX you are using XMLHTTP requests to get the data anyway, which returns the data as XML using the
responseXML
property.
Simplicity
Ok both XML and JSON are pretty simple. I find XML easier to write and read myself.
Extensibility
They don’t put the X in XML for nothing.
Interoperability and Data Exchange
On the server JSON requires platform / language specific converters. XML has the lovely XSL-T which is not only widely supported but it is really fast on the client AND server. This is a big plus for AJaX to have the ability to process the same data on either the client or server with one XSL-T file so there is no re-writing or converting code.
Structure and Data Types
Sure JSON has something that you could consider structure but XML has a little something called a schema which is widely supported and a necessity that allows definition of data structure as well as data types.
Data Size
In the extreme both formats could be encoded to be essentially the same. We use an encoded format for our AJaX applications which is about as small as you can get without zipping or ignoring the data.
Emerging Technologies
E4X anyone? (thanks for the link Dan)
Acronyms
Yes, you would need to change AJaX to AJaJ if you wanted to use JSON and it doesn’t really roll off the tongue.
One can really see the benefit of XML when you consider dealing with large datasets for something like an AJaX grid control. For example, a common operation in a data grid is sorting - not only is it faster to sort using XSL-T rather than an array of JavaScript objects but the exact same XSL-T can by used to sort the data on either the server or client in different situations. To investigate this further I wrote some JavaScript to test the performance of
eval()
ing JSON data and compared it to the performance of the same data in XML being processed using XSL-T. The script essentially generated data sets in both XML and JSON formats with varying numbers of records and then procesed them accordingly into HTML fragments to be inserted into the DOM using
innerHTML
. Both tests were done in IE6 on Win2K (didn’t get around to Firefox or Opera:(). The results are illustrated below.
As is plain to see the XML data is processed much faster - especially as we move to larger data sets. This makes sense since once the data is ready it is transformed using a fast XSL-T stylesheet which outputs XHTML. On the other hand for JSON one needs to apply the slow
eval()
function to the data after which the JavaScript objects have to be looped through and concatenated into a string. Admittedly, if for some reason you actually want to deal with a singular JavaScript object (ie not having many records that are being put straight into XHTML) then JSON may be the way to go.
A second interesting thing I noticed here was that using a data-driven XSL-T stylesheet rather than a declaritive one resulted in noticeably slower transformations (though still much faster than JSON). I expected this result but did not expect it to be so evident. The reason for this is because a data-driven stylesheet uses many
<xsl:apply-templates select="*" />
and
<xsl:template match="nodeName" />
whereas a declaritive one uses only one
<xsl:template match="/" />
for the root node and many nested
<xsl:for-each select="nodeName" />
.
Posted in Web2.0, AJAX, XML, XSLT | 11 Comments »

 Entries (RSS)
and
Entries (RSS)
and